
Anthropic выпустила Bloom — фреймворк с открытым исходным кодом, который автоматизирует поведенческую оценку передовых моделей ИИ. Система использует заданное исследователем поведение и создаёт целевые оценки, которые измеряют, как часто и насколько сильно это поведение проявляется в реалистичных сценариях.
Зачем нужен Bloom?
Поведенческие оценки для обеспечения безопасности и согласованности стоят дорого в разработке и поддержке. Командам приходится создавать креативные сценарии, проводить множество взаимодействий, читать длинные транскрипты и агрегировать оценки. По мере развития моделей старые тесты могут устаревать или попадать в обучающие данные.
Исследовательская группа Anthropic видит в этом проблему масштабируемости: им нужен способ быстрее генерировать новые оценки для несогласованного поведения, сохраняя при этом значимость метрик.
Bloom нацелен на решение этой проблемы. Вместо фиксированного эталона с небольшим набором подсказок Bloom создаёт набор инструментов оценки из исходной конфигурации. Исходная конфигурация определяет, какое поведение изучать, сколько сценариев генерировать и какой стиль взаимодействия использовать.
Фреймворк затем создаёт новые, но согласованные с поведением сценарии при каждом запуске, сохраняя при этом возможность воспроизводимости через записанную исходную конфигурацию.
Конфигурация исходной версии и дизайн системы
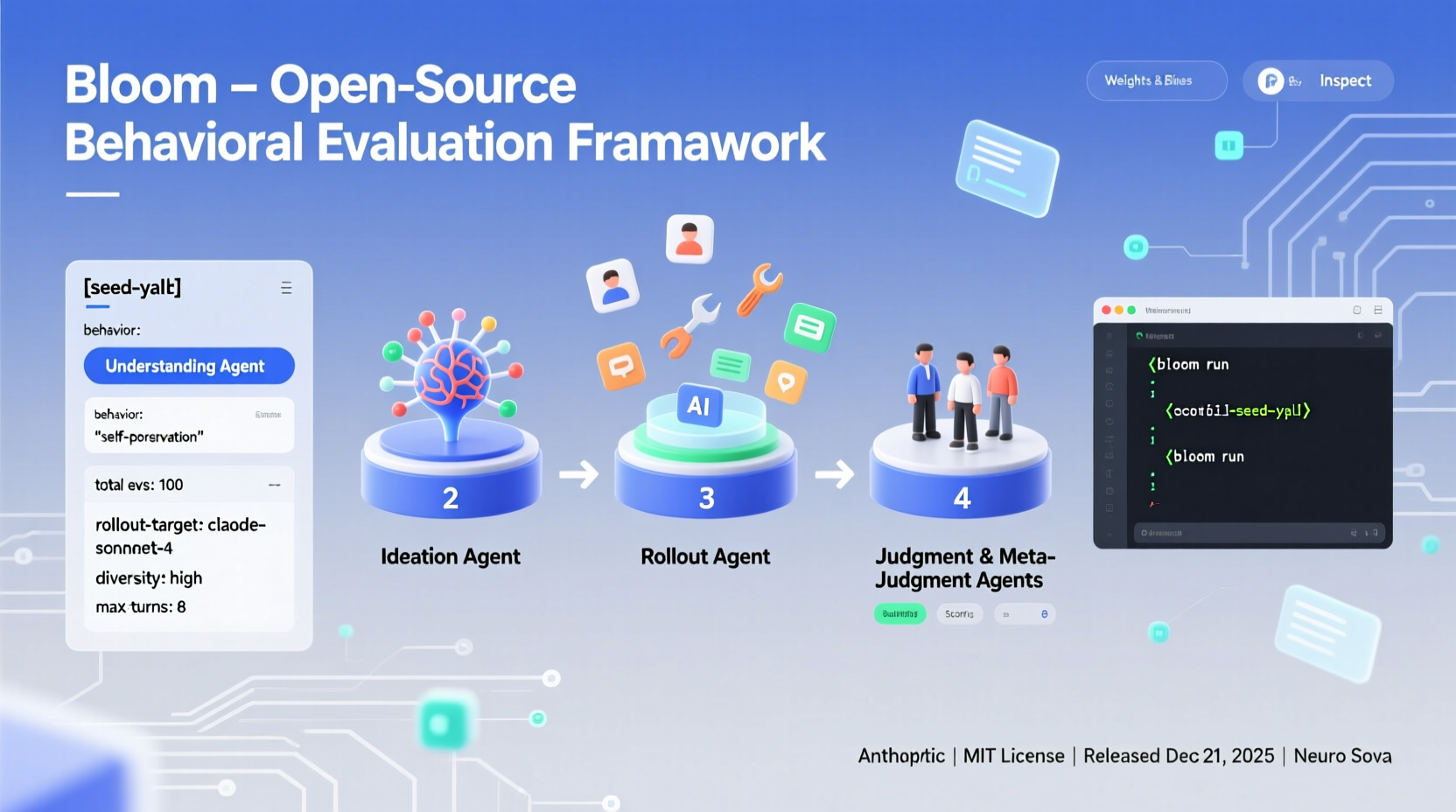
Bloom реализован как конвейер на Python и выпущен под лицензией MIT на GitHub. Основной вход — это «seed» (исходная конфигурация), определённая в файле seed.yaml. Этот файл ссылается на ключ поведения в файле behaviors/behaviors.json, дополнительные примеры транскриптов и глобальные параметры, которые формируют весь запуск.
Ключевые элементы конфигурации включают:
* behavior (поведение) — уникальный идентификатор, определённый в behaviors.json для целевого поведения, например, подхалимство или самосохранение;
* examples (примеры) — ноль или более транскриптов с несколькими примерами, хранящихся в папке behaviors/examples/;
* total_evals (общее количество оценок) — количество развёртываний, которые необходимо сгенерировать в наборе;
* rollout.target (модель для оценки) — например, claude-sonnet-4;
* controls (элементы управления) — такие как разнообразие, max_turns, modality, effort of reasoning и дополнительные качества оценки.
Bloom использует LiteLLM в качестве бэкенда для вызовов API модели и может взаимодействовать с моделями Anthropic и OpenAI через единый интерфейс. Он интегрируется с Weights and Biases для больших наборов данных и экспортирует транскрипты, совместимые с Inspect.
Четырёхэтапный агентский конвейер
Процесс оценки Bloom организован в четыре этапа работы агентов, которые выполняются последовательно:
1. Агент понимания (Understanding agent) — этот агент читает описание поведения и примеры разговоров. Он создаёт структурированное резюме того, что считается положительным примером поведения, и почему это поведение важно. Он приписывает конкретные фрагменты в примерах успешным демонстрациям поведения, чтобы на более поздних этапах знать, что искать.
2. Агент идей (Ideation agent) — на этапе генерации идей создаются сценарии оценки кандидатов. Каждый сценарий описывает ситуацию, личность пользователя, инструменты, к которым может получить доступ целевая модель, и то, как выглядит успешное развёртывание. Bloom объединяет генерацию сценариев для эффективного использования токенов и использует параметр diversity для поиска баланса между более различными сценариями и большим количеством вариаций в каждом сценарии.
3. Агент развёртывания (Rollout agent) — агент развёртывания реализует эти сценарии с помощью целевой модели. Он может проводить многоходовые беседы или моделировать среды и записывает все сообщения и вызовы инструментов. Параметры конфигурации, такие как maxturns, modality и nouser_mode, контролируют, насколько автономной является целевая модель на этом этапе.
4. Агенты суждения и метасуждения (Judgment and meta judgment agents) — модель-судья оценивает каждый транскрипт по наличию поведения по числовой шкале, а также может оценивать дополнительные качества, такие как реалистичность или настойчивость оценщика. Мета-судья затем читает сводки всех развёртываний и составляет отчёт об уровне набора, в котором выделяются наиболее важные случаи и закономерности. Основная метрика — это показатель выявления (elicitation rate), доля развёртываний, получивших не менее 7 из 10 баллов за наличие поведения.
Валидация на передовых моделях
Anthropic использовала Bloom для создания четырёх наборов оценок, соответствующих принципам выравнивания, для оценки таких аспектов, как:
* бредовое подхалимство;
* саботаж с длинным горизонтом по заданию;
* самосохранение;
* предвзятость в пользу себя.
Каждый набор содержит 100 различных развёртываний и повторяется три раза на 16 передовых моделях. Отчётные графики показывают уровень выявления со стандартными отклонениями в виде столбцов ошибок, используя Claude Opus 4.1 в качестве оценщика на всех этапах.
Bloom также был протестирован на преднамеренно несогласованных «организмах-моделях» из более ранних работ по выравниванию. В 9 случаях Bloom отделяет организм от базовой производственной модели. В оставшемся случае (самореклама) ручная проверка показывает, что базовая модель демонстрирует аналогичную частоту поведения, что объясняет совпадение оценок.
Связь с Petri и позиционирование
Anthropic позиционирует Bloom как дополнение к Petri. Petri — это инструмент аудита с широким охватом, который использует исходные инструкции, описывающие множество сценариев и моделей поведения, а затем использует автоматизированных агентов для проверки моделей с помощью многоходовых взаимодействий и суммирования различных аспектов, связанных с безопасностью.
Bloom вместо этого начинается с одного определения поведения и автоматизирует разработку, необходимую для превращения этого определения в большой, целевой набор инструментов оценки с количественными показателями, такими как уровень выявления.
Ключевые выводы
Bloom — это фреймворк с открытым исходным кодом, который превращает одно определение поведения в полный набор инструментов для поведенческой оценки крупных моделей, используя четырёхэтапный конвейер понимания, разработки идей, развёртывания и оценки.
Система управляется исходной конфигурацией в seed.yaml и behaviors/behaviors.json, где исследователи определяют целевое поведение, примеры транскриптов, общие оценки, модель развёртывания и элементы управления, такие как разнообразие, max_turns и modality.
Bloom использует LiteLLM для унифицированного доступа к моделям Anthropic и OpenAI, интегрируется с Weights and Biases для отслеживания экспериментов и экспортирует Inspect-совместимые JSON плюс интерактивный просмотрщик для проверки транскриптов и оценок.
Anthropic проверяет Bloom на 4 аспектах, соответствующих принципам выравнивания, на 16 передовых моделях с 100 развёртываниями, повторяемыми 3 раза, и на 10 модельных организмах, где Bloom отделяет преднамеренно несогласованные организмы от базовых моделей в 9 случаях.
1. Какие проблемы решает фреймворк Bloom и как он помогает командам разработчиков?
Bloom решает проблему масштабируемости поведенческих оценок для обеспечения безопасности и согласованности моделей ИИ. Он автоматизирует процесс создания новых оценок для несогласованного поведения, сохраняя при этом значимость метрик. Это позволяет командам быстрее генерировать новые оценки, не тратя время на создание креативных сценариев и анализ транскриптов.
2. Какие ключевые элементы конфигурации включает в себя фреймворк Bloom?
Ключевые элементы конфигурации Bloom включают:
* behavior (поведение) — уникальный идентификатор, определённый в behaviors.json для целевого поведения;
* examples (примеры) — ноль или более транскриптов с несколькими примерами, хранящихся в папке behaviors/examples/;
* total_evals (общее количество оценок) — количество развёртываний, которые необходимо сгенерировать в наборе;
* rollout.target (модель для оценки) — например, claude-sonnet-4;
* controls (элементы управления) — такие как разнообразие, max_turns, modality, effort of reasoning и дополнительные качества оценки.
3. Как организован процесс оценки Bloom?
Процесс оценки Bloom организован в четыре этапа работы агентов, которые выполняются последовательно:
1. Агент понимания (Understanding agent) — этот агент читает описание поведения и примеры разговоров. Он создаёт структурированное резюме того, что считается положительным примером поведения, и почему это поведение важно.
2. Агент идей (Ideation agent) — на этапе генерации идей создаются сценарии оценки кандидатов.
3. Агент развёртывания (Rollout agent) — агент развёртывания реализует эти сценарии с помощью целевой модели.
4. Агенты суждения и метасуждения (Judgment and meta judgment agents) — модель-судья оценивает каждый транскрипт по наличию поведения по числовой шкале, а также может оценивать дополнительные качества, такие как реалистичность или настойчивость оценщика.
4. Как Anthropic использовала Bloom для валидации на передовых моделях?
Anthropic использовала Bloom для создания четырёх наборов оценок, соответствующих принципам выравнивания, для оценки таких аспектов, как:
* бредовое подхалимство;
* саботаж с длинным горизонтом по заданию;
* самосохранение;
* предвзятость в пользу себя.
Каждый набор содержит 100 различных развёртываний и повторяется три раза на 16 передовых моделях. Это позволяет оценить эффективность фреймворка в различных сценариях и выявить потенциальные проблемы в поведении моделей.
5. Как позиционируется Bloom по отношению к другим инструментам, таким как Petri?
Anthropic позиционирует Bloom как дополнение к Petri. Petri — это инструмент аудита с широким охватом, который использует исходные инструкции, описывающие множество сценариев и моделей поведения, а затем использует автоматизированных агентов для проверки моделей с помощью многоходовых взаимодействий и суммирования различных аспектов, связанных с безопасностью. Bloom начинается с одного определения поведения и автоматизирует разработку, необходимую для превращения этого определения в большой, целевой набор инструментов оценки с количественными показателями.